이번 포스팅에서는 저번 포스팅에 이어 해당 데이터를 전처리한 과정을 소개합니다.
사용한 데이터는 kaggle의 e-commerce 데이터입니다.
* 전체 코드는 여기에서 확인하실 수 있습니다.
저번 포스팅에서, 컬럼명 변경, 결측치 처리 등 기본적인 전처리를 진행했습니다.
이어서 구매가 많은 지역을 보여주는 worldmap을 그려보고, 각 컬럼의 대략적인 통계 정보를 보기 위해 heatmap을 그려보았는데요.
heatmap을 그려봄으로써 unit_price, quantity < 0인 경우가 있음을 발견했습니다.
이번 포스팅에서는 quantity < 0가 발생한 경우를 확인하여 처리한 과정에 대해서 적어보도록 하겠습니다.
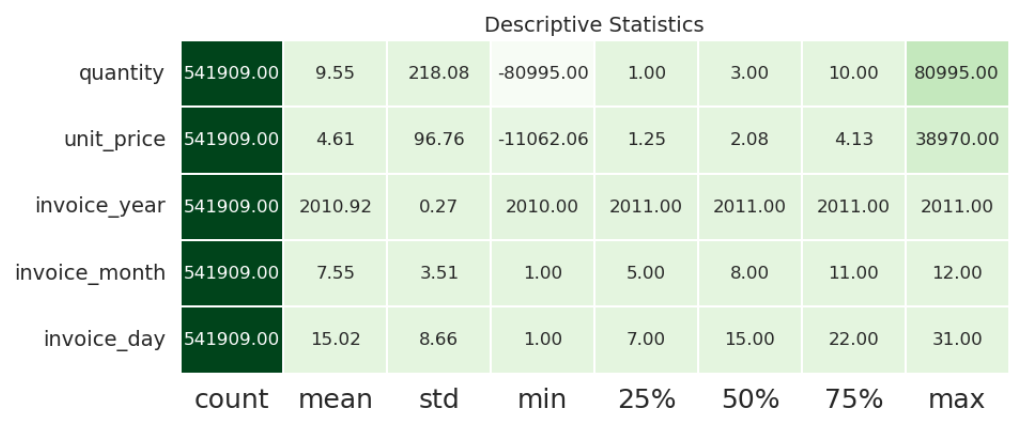
📃 추가 확인 및 전처리
추후 CLV(Customer Lifetime Value)를 계산하는 과정에서는 quantity > 0인 행만 사용할 예정입니다만,
전처리 전 quantity < 0 또는 unit_price < 0 인 행이 어떤 의미인지에 대해서 확인하고자 했습니다.
Quantity
df_LTV_01[df_LTV_01['quantity'] < 0].sample(5) # quantity < 0인 경우 확인
📌 invoice_no 가장 앞에 C가 있으면 취소한 내역, 취소했을 시 quantity < 0
📌 C 뒤 번호로 어떤 내역을 취소한 건지 확인하기 어려움 (해당하는 invoice_no 없음)
📌 주문 전체 취소 = 그 주문번호 앞에 C가 붙음, 아니라면 아예 새로운 주문번호 + C 를 부여하는 것으로 보임
df_LTV_01[df_LTV_01['unit_price'] == 0].sample(5) # unit_price == 0인 경우 확인
Unit_price에 대해서 좀 더 확인해봤습니다.
unit_price < 0 인 경우는 stock_code = 'B'인 경우였으며, 이는 구매 내역은 아니고 Bad debt를 조정하기 위해 들어간 내역으로 보입니다.
customer_id가 NaN인 경우였기 때문에 어차피 드랍될 예정이라 크게 중요하진 않아보입니다.
df_LTV_01[df_LTV_01['unit_price'] < 0].head() # unit_price < 0인 경우 확인
df_base[df_base['stock_code'] == 'B'] # unit_price < 0 인 상품 확인
# stock_code = 'B'인 상품: Adjust bad debt <- 즉, 구매 내역은 아님
# 어차피 customer_id = NaN이기 때문에 추후 드랍할 예정
df_base[df_base['stock_code'] == '22034'] # unit_price == 0 인 상품 확인
📌 unit_price = 0인 이유에 대해 확정짓기 어려움
📌 같은 stock_code인데도 unit_price = 0 인 경우 존재
📌 unit_price = 0 인 경우 중 customer_id이 NaN이었던 경우가 대부분이긴 했으나, 이유를 추측하기 어려움
_unit_price = 0인 경우에 대한 추측
1. 단기성 이벤트로 해당 상품을 무료로 증정한 적이 있었다
2. 프로모션이 진행됨에 따라 같은 stock_code여도 unit_price가 다를 수 있다
📃 최종 전처리 - CLV 계산에 활용할 형태로 만들기
CLV 계산에 활용할 수 있는 transaction data의 형태로 만듭니다.
- total_price 행 추가
- customer_id가 결측치였을 경우 drop
- quantity > 0인 행만 남김
- 사용할 열(invoice_date, customer_id, total_price)만 남김
## rollback을 위해 copy
df_LTV_02 = df_LTV_01.copy()
# ## total_price = quantity * unit_price 열 추가
df_LTV_02['total_price'] = df_LTV_02['quantity'] * df_LTV_02['unit_price']
## customer_id == '0'인 경우 drop
df_LTV_02 = df_LTV_02[ df_LTV_02['customer_id'] != '0']df_LTV_03 = df_LTV_02[df_LTV_02['quantity'] > 0]
## 사용할 열만 남기기
df_LTV_03 = df_LTV_03[['invoice_date', 'customer_id', 'total_price']]
Outlier와 중복 데이터
CLV를 계산하는 경우이므로 Outlier에 대한 처리는 따로 진행하지 않았습니다.
- 본래 구매 데이터는 비대칭적임
- Gamma-gamma model에서 구매의 불규칙성을 감안하여 모델링하게 됨
중복데이터임을 확인할 수 있는 근거가 명확하지 않기 때문에 중복데이터도 따로 처리하지 않았습니다.
혹시 이전 포스팅이 궁금하시다면 아래 링크를 확인해주세요!
[개인프로젝트] 고객 LTV(Life Time Value) 예측 - 데이터 전처리
이번 포스팅에서는 해당 데이터를 전처리한 과정을 소개합니다. 사용한 데이터는 kaggle의 e-commerce 데이터입니다. * 전처리 전체 코드는 여기에서 확인하실 수 있습니다. 📃 데이터 전처리 내가
youngfromkorea.tistory.com
참고자료
'데이터 분석 > 프로젝트' 카테고리의 다른 글
| [클론 프로젝트] 타이타닉 시각화/랜덤포레스트로 생존 여부 예측하기 (0) | 2023.06.30 |
|---|---|
| [개인프로젝트] CLV(Customer Lifetime Value) 예측 - 데이터 전처리 (0) | 2023.04.22 |
| [개인프로젝트] CLV(Customer Lifetime Value) 예측 - 목표 및 계획 (2) | 2023.04.19 |